Scribe从各种数据源上收集数据,放到一个共享队列上,然后push到后端的中央存储系统上。当中央存储系统出现故障时,scribe可以暂时把日志写到本地文件中,待中央存储系统恢复性能后,scribe把本地日志续传到中央存储系统上。需要注意的是,各个数据源须通过thrift(由于采用了thrift,客户端可以采用各种语言编写)向scribe传输数据(每条数据记录包含一个分类category和一条信息message),可以在scribe配置文件中配置用于监听端口的thrift线程数(默认3)。
在后端,scribe可以将不同category的数据存放到不同目录中,以便于进行分别处理。后端的日志存储方式可以是各种各样的store,包括file(文件),buffer(双层存储,一个主储存,一个副存储),network(另一个scribe服务器),bucket(包含多个store,通过hash的将数据存到不同store中),null(忽略数据),thriftfile(写到一个Thrift TFileTransport文件中)和multi(把数据同时存放到不同store中)。
scribe架构图如下: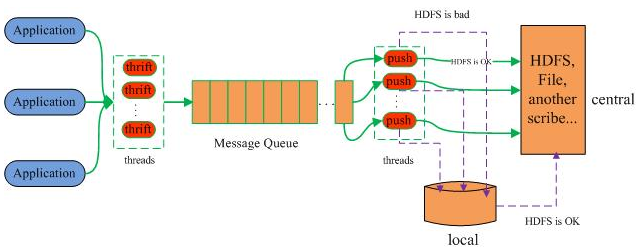
1、scribe中常用store存储介绍
file
将日志写到文件或者NFS中,支持两种文件格式,即std和hdfs即普通文本文件和HDFS。
buffer
最常用的一种store。该store中包含两个子store,其中一个是primary store,另一个是secondary store。日志会优先写到primary store中,如果primary store出现故障,则scribe会将日志暂存到secondary store中,待primary store恢复性能后,再将secondary store中的数据拷贝到primary store中。
null
用户可以在配置文件中配置一种叫default的category,如果数据所属的category没有在配置文件中设置相应的存储方式,则该数据会被当做default,如果用户想忽略这样的数据,可以将它放入null store中。
2、配置文件解析 Scribe的配置文件由全局的section和一个或多个store的section组成,在源码包的examples目录下有多个配置文件实例可以参考。
1)、全局配置项
port: (number)
scribe监听的端口,当然也可以通过命令参数-p指定
max_msg_per_second: (number) 每秒最大日志并发数,默认为0,0则表示没有限制
max_queue_site:(byte) 队列最大可以为多少,默认为5,000,000 bytes
check_interval:(second) 检查存储的频率,默认为5s
new_thread_per_category:(yes/no) 是否为每个一个分类创建一个线程,为no的话,只创建一个线程为每个存储服务,默认为yes
num_thrift_server_threads:(number) 接收消息的线程数,默认为3
比如可以这样配置
1 | port=1463 |
2)、局部配置项,主要是store相关的配置。
1 | cateogry: 哪些消息由这个category的store处理 |
比如这些参数可以这样使用
1 | <store> |
不同的类型的store配置有区别,上面的配置参数只是一些通用参数。
a)、file store
1 | file_path 默认路径是‘/tmp’。 |
比如实际使用中可以这样配置
1 | <store> |
b)、Network Store network store向其它scribe server发送消息,Scribe保持持久的链接打开以至于它能够发送消息,在正常运行的情况下,scribe会基于当前缓存中存在多少条消息等待发送而分批次的发送。
1 | remote_host 远程主机的ip或者名称。 |
比如实际使用中可以这样配置
1 | <primary> |
c、Bucket Store
buffer store中包含两个子store:primary和secondary,日志会先尝试写到primary store中,如果primary store出现故障,则scribe会将日志暂存到secondary store中,待primary store恢复性能后,再将secondary store中的数据拷贝到primary store中(除非replay_buffer=no),其中secondary store仅支持两种store(file和null)。
1 | buffer_send_rate 默认是1,在check_interval周期内,执行多少次secondary store读出一组消息并且发送到primary store中。 |
比如实际使用中可以这样配置
1 | <store> |
d、Bucket Store bucket stores使用消息前缀作为key,将消息hash到多个文件中去(具体我没有用过,不知道效果怎样)。
1 | num_buckets 默认值是1,hash到buckets的个数,不能被hash进bucket的消息将被放入一个特别的0号bucket。 |
配置实例
1 | <store> |
e、Null Store
1 | Null store告诉scribe对给定的category,忽略所有的消息。 |
配置实例
1 | <store> |
f、Multi Store 一个multi store会将消息转发到多个子stores中去,子store以“store0”, “store1”, “store2”命名。
1 | report_success 值可以是all或者any,默认是any,是否所有substores或任何substores必须成功地记录消息。 |
配置实例
1 | <store> |
关于scribe的资料网上不是很多,可能是用的人少吧,我也是查询了相关资料及结合实际使用经验写下了这篇文章。